ZPL is an array programming language designed
from first principles for fast execution on both sequential and
parallel computers. It provides a convenient high-level
programming medium for supercomputers and large-scale clusters
with efficiency comparable to hand-coded message passing. It is
the perfect alternative to using a sequential language like C or
Fortran and a message passing library like MPI.
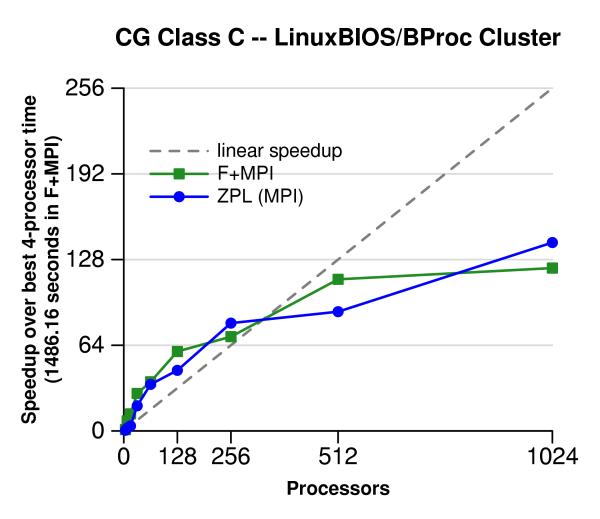
In parallel programming, the buck stops at performance. The whole reason to parallelize a code is to make it run faster. If the high-level language hurts either the sequential performance or the program's ability to scale to higher numbers of processors, then it loses its value. The figure to the left shows the performance of the NAS CG benchmark on a 1024-node cluster at Los Alamos National Laboratory. It compares our ZPL port (ZPL) with the provided Fortran and MPI implementation (F+MPI). In this experiment, the ZPL compiler generated C code with MPI calls. Both implementations show comparable performance all the way up to 1024 processors.
More performance results are available here. This graph first appeared in PPoPP '03 in a paper entitled The Design and Implementation of a Parallel Array Operator for the Arbitrary Remapping of Data. For a more in-depth discussion of the CG benchmark, please refer to this paper.
Because ZPL compiles to ANSI C with calls to the user's choice of communication library (including MPI), ZPL is highly portable. However, merely being able to run on most parallel computers is only half of being portable. Portability only counts if the performance is portable too. Thus ZPL uses MPI to run on most clusters and almost every machine but, in the portable-performance sense, is more portable than MPI.
As have others, we made this argument at P-PHEC '04 in a paper entitled The High-Level Parallel Language ZPL Improves Productivity and Performance:
"When programmers write MPI message passing code directly, it is the semantics of message passing not the individual implementations of MPI that ultimately limit performance. For example, data that is irregularly laid out in memory, must be marshaled and brought together into a contiguous message buffer before it can be sent. However, some libraries (such as SHMEM and ARMCI) and PC networks interfaces (such as Dolphin SCI and Quadrics Elan) expose via their native communication library remote direct memory access (RDMA) to remote addresses. These do not require the extra copy and memory overhead. An implementation of MPI using these facilities has no control over this data marshaling because the code to perform this operation is embedded in the program itself. If a ZPL program is to be run using MPI, then the ZPL libraries for MPI would perform the marshaling; on a machine with efficient RDMA, no marshaling would be performed.
"By removing the burden of writing low-level implementing code such as communication calls, the compiler is able to better optimize communication using data dependence information. Moreover, the late binding to the native communication library allows for the most efficient communication library to be used without penalties incurred when using a particular library."
Though lines of code is not an ideal metric for evaluating a parallel programming language, it does provide some quantitative measure of programmability. Consider that our ZPL port of the NAS CG benchmark is 73 lines of code and the provided Fortran and MPI program is 240 lines of code. Note that these are the identical codes that were used for the performance numbers above. The ZPL code requires less than one third the number of lines used to write the equivalent Fortran and MPI.
These line counts are not proof that ZPL is easier to use, but do provide a small testament to how much easier it is to use ZPL than MPI. You can learn more about ZPL by