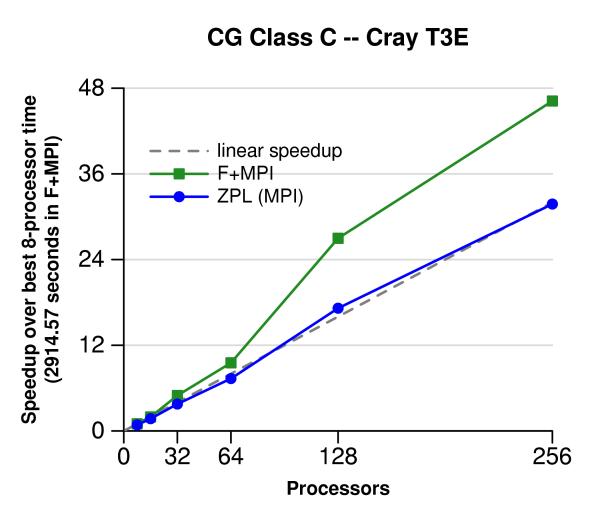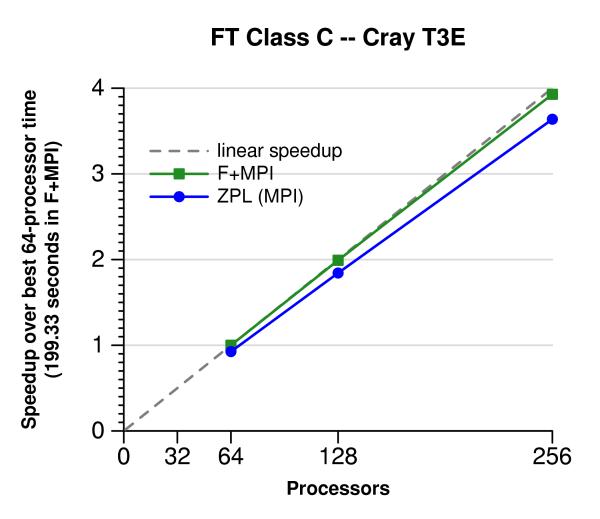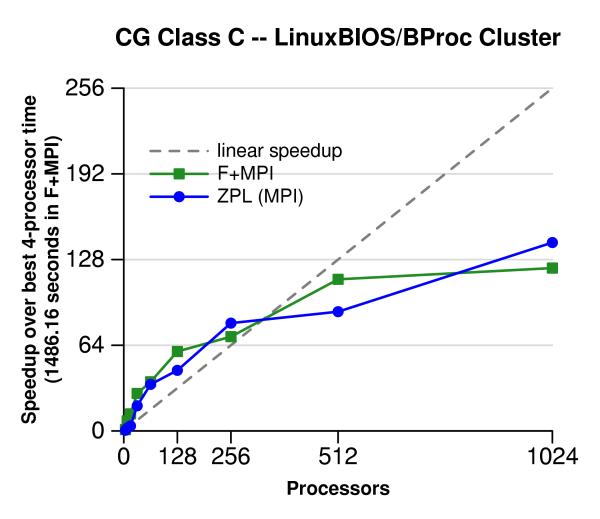
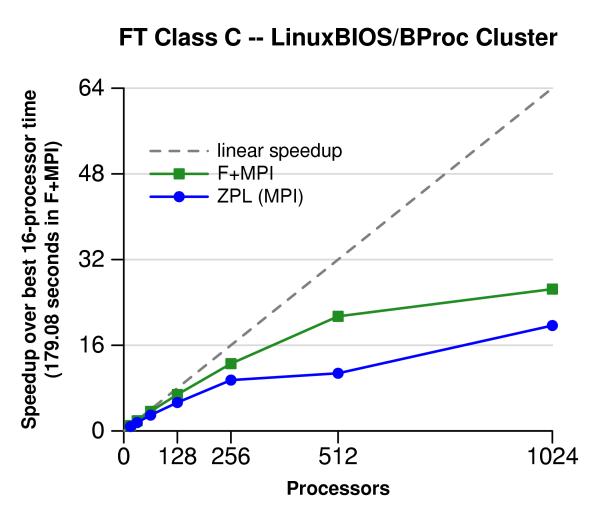
This page shows the performance of the NAS CG and FT benchmarks in ZPL and Fortran + MPI across three platforms: a cluster of commodity processors, an IBM SP2, and a Cray T3E. For consistency with Fortran + MPI in these experiments, MPI is always the chosen communication target of ZPL. On all the platforms and in both benchmarks, ZPL is competitive with the Fortran + MPI. The real benefit to using ZPL comes from its easier-to-master programming model.
The performance results illustrated here were previously published in PPoPP '03 in a paper entitled The Design and Implementation of a Parallel Array Operator for the Arbitrary Remapping of Data.
The following graphs show results on Pink, a 1024-node cluster at Los Alamos National Laboratory in Los Alamos, New Mexico. The cluster is based on the LinuxBIOS/BProc technology and was built by the ACL Cluster Research Group. Each node has 2 GB of memory and two 2.4 GHz Intel Xeon processors.
The following graphs show results on Icehawk, a 200-processor IBM SP2 with 176 user-processors, located at the Arctic Region Supercomputer Center in Fairbanks, Alaska. The SP2 is composed of 44 nodes with 2 GB of memory and four 375 MHz power3 processors.
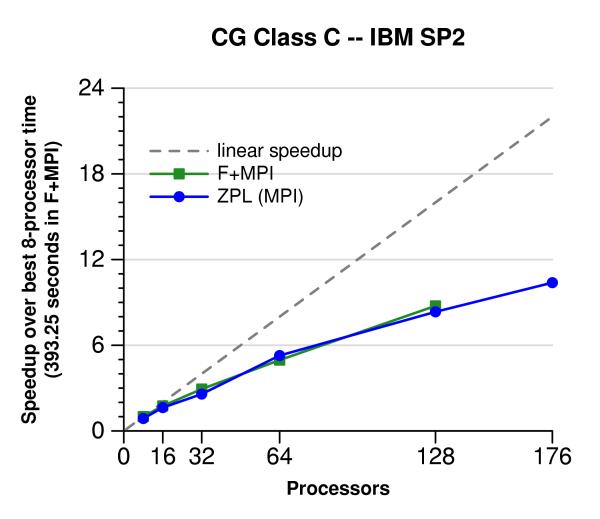
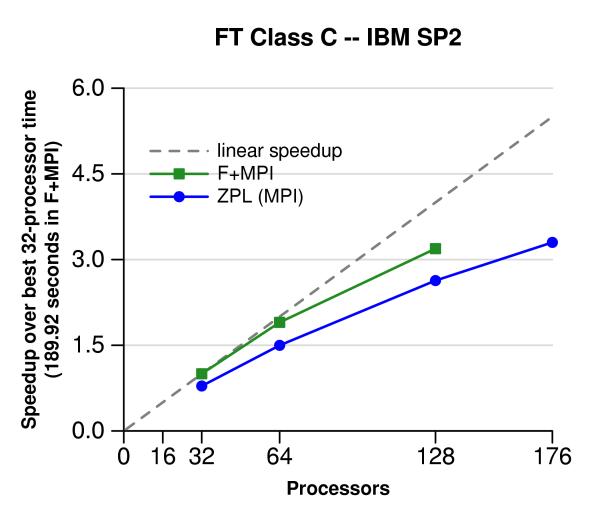
The following graphs show results on Yukon, a 272-processor Cray T3E with 260 user-processors, located at the Arctic Region Supercomputer Center in Fairbanks, Alaska. Each processor is a 450 MHz Alpha processor with 256 MB of memory.